SteadyDancer
Harmonized and Coherent Human Image Animation
with First-Frame Preservation
Jiaming Zhang1, Shengming Cao2, Rui Li2, Xiaotong Zhao2, Yutao Cui2,
Xinglin Hou, Gangshan Wu1, Haolan Chen2, Yu Xu2, Limin Wang1,3†, Kai Ma2†
1State Key Laboratory for Novel Software Technology, Nanjing University
2Platform and Content Group (PCG), Tencent
3OpenGVLab, Shanghai AI Laboratory
†Corresponding author.
Abstract
Preserving first-frame identity while ensuring precise motion control is a fundamental challenge in human image animation. The Image-to-Motion Binding process of the dominant Reference-to-Video (R2V) paradigm overlooks critical spatio-temporal misalignments common in real-world applications, leading to failures such as identity drift and visual artifacts.
We introduce SteadyDancer, an Image-to-Video (I2V) paradigm-based framework that achieves harmonized and coherent animation and is the first to ensure first-frame preservation robustly. Firstly, we propose a Condition-Reconciliation Mechanism to harmonize the two conflicting conditions, enabling precise control without sacrificing fidelity. Secondly, we design Synergistic Pose Modulation Modulesto generate an adaptive and coherent pose representation that is highly compatible with the reference image. Finally, we employ a Staged Decoupled-Objective Training Pipeline that hierarchically optimizes the model for motion fidelity, visual quality, and temporal coherence.
Experiments demonstrate that SteadyDancer achieves state-of-the-art performance in both appearance fidelity and motion control, while requiring significantly fewer training resources than comparable methods.
Motivation
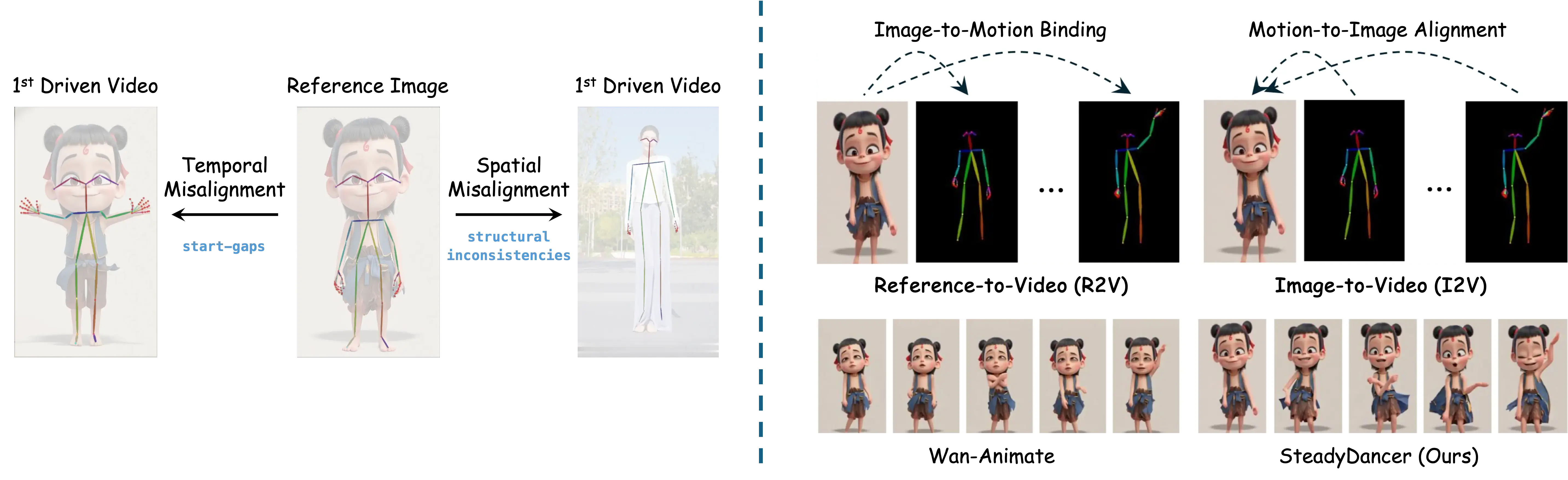
Spatio-temporal Misalignments
We identify and tackle the prevalent issues of spatial-structural inconsistencies and temporal start-gapsbetween source images and driving videos common in real-world scenarios, which often lead to identity drift in generated animations.
Image-to-Video (I2V) v.s. Reference-to-Video (R2V) paradigm
The R2V paradigm treats animation as binding a reference image to a driven pose. However,this relaxation of alignment constraints fails under spatio-temporal misalignments, causing artifacts and abrupt transitions in spatial inconsistencies or temporal start-gap scenarios. Conversely, the I2V paradigm is superior as it inherently guarantees first-frame preservation, and its Motion-to-Image Alignment ensures high-fidelity and coherent video generation starting directly from the reference state.
Method
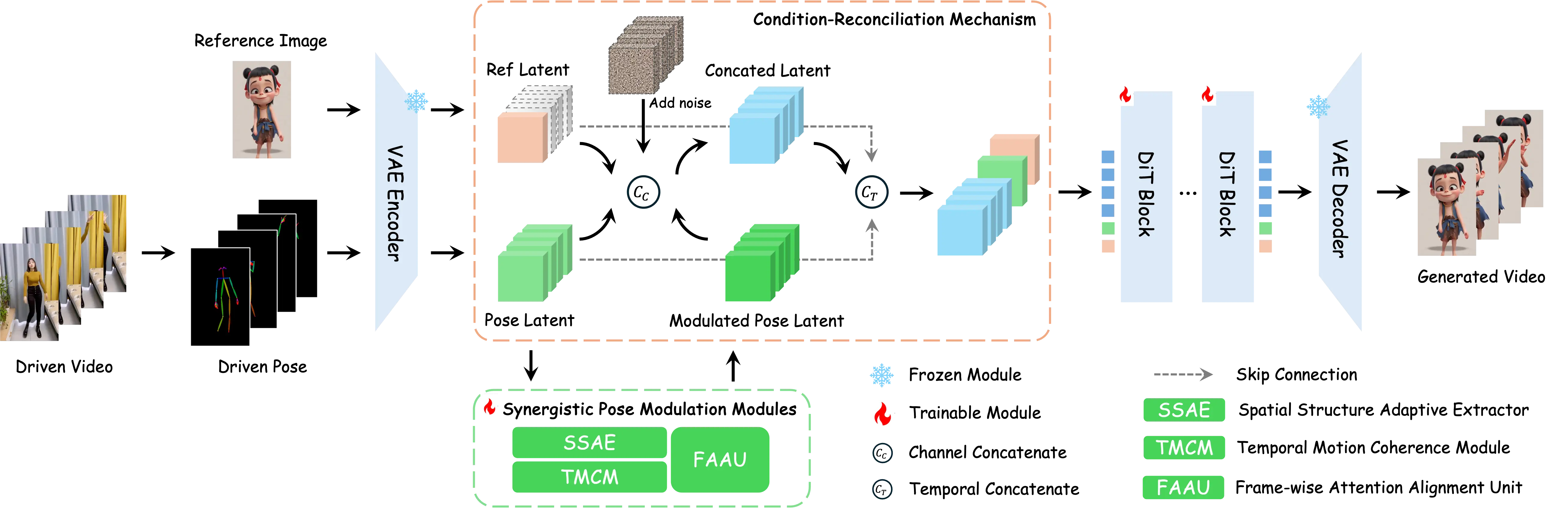
An overview of SteadyDancer, a Human Image Animation framework based on the Image-to-Video (I2V) paradigm. First, it employs a Condition-Reconciliation Mechanism to reconcile appearance and motion conditions, achieving precise control without sacrificing first-frame preservation. Second, it utilizes Synergistic Pose Modulation Modules to resolve critical spatio-temporal misalignments. Finally, we employ a Staged Decoupled-Objective Training Pipeline that hierarchically optimizes the model for motion fidelity, visual quality, and temporal coherence.
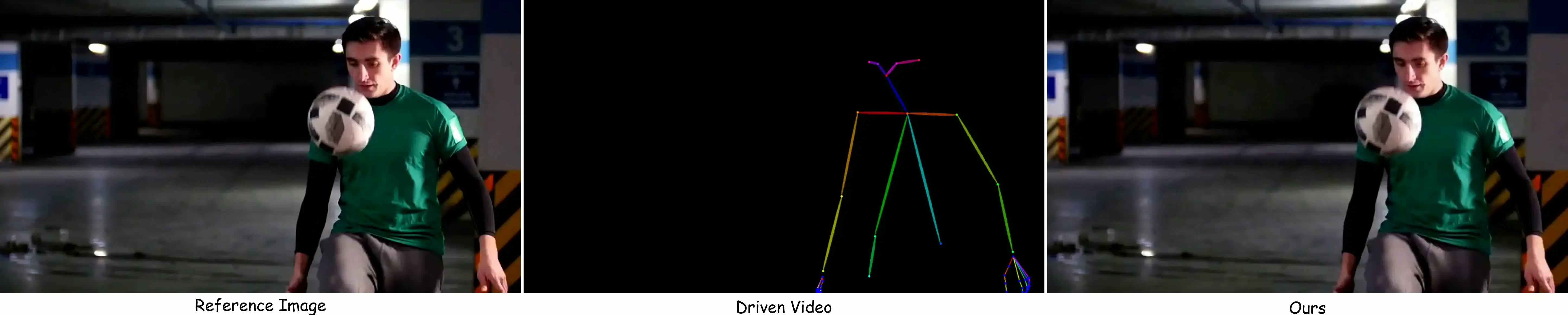
Cases in X-Dance Benchmark
The X-Dance Benchmark, which focus on 1) the spatio-temporal misalignments by different-source image-video pairs; and 2) visual identity preservation, temporal coherence, and motion accuracy by complex motion and appearance variations.









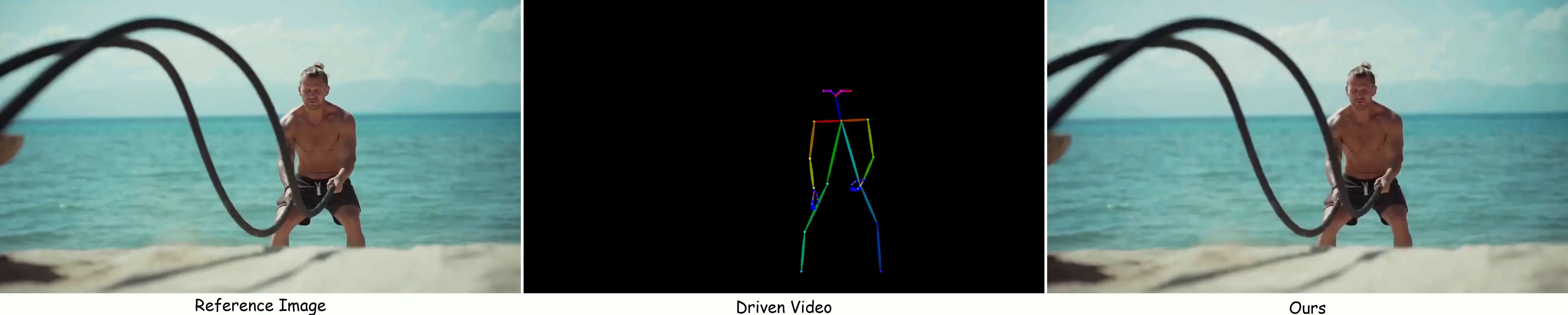
RealisDance-Val Benchmark
Cases in RealisDance-Val Benchmark
The RealisDance-Val Benchmark, which focus on 1) real-world dance videos with same-source image-video pairs; and 2) synthesize realistic object dynamics that are physically consistent with the driving actions.





X-Dance Benchmark
To fill the void left by existing same-source benchmarks (such as TikTok), which fail to evaluate spatio-temporal misalignments, we propose X-Dance, a new benchmark that focuses on these challenges. The X-Dance benchmark is constructed from diverse image categories (male/female/cartoon, and upper-/full-body shots) and challenging driving videos (complex motions with blur and occlusion). Its curated set of pairings intentionally introduces spatial-structural inconsistencies and temporal start-gaps, allowing for a more robust evaluation of model generalization in the real world.
You can download the X-Dance benchmark from Hugging Face.
BibTeX
@misc{zhang2025steadydancer,
title={SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation},
author={Jiaming Zhang and Shengming Cao and Rui Li and Xiaotong Zhao and Yutao Cui and Xinglin Hou and Gangshan Wu and Haolan Chen and Yu Xu and Limin Wang and Kai Ma},
year={2025},
eprint={2511.19320},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.19320},
}The images used in the demo videos are for academic purposes only and are not for commercial use. If you feel that the images we use infringe your rights, please contact us and we will delete them immediately and express our sincere apologies. The source code of this webpage is borrowed from the Nerfies project webpage.